Training AI-powered Virtual Agents
Enterprise Virtual assistants can be launched once they are fully trained. However, for that to happen, they need to interact with real users (which can only happen post-launch).
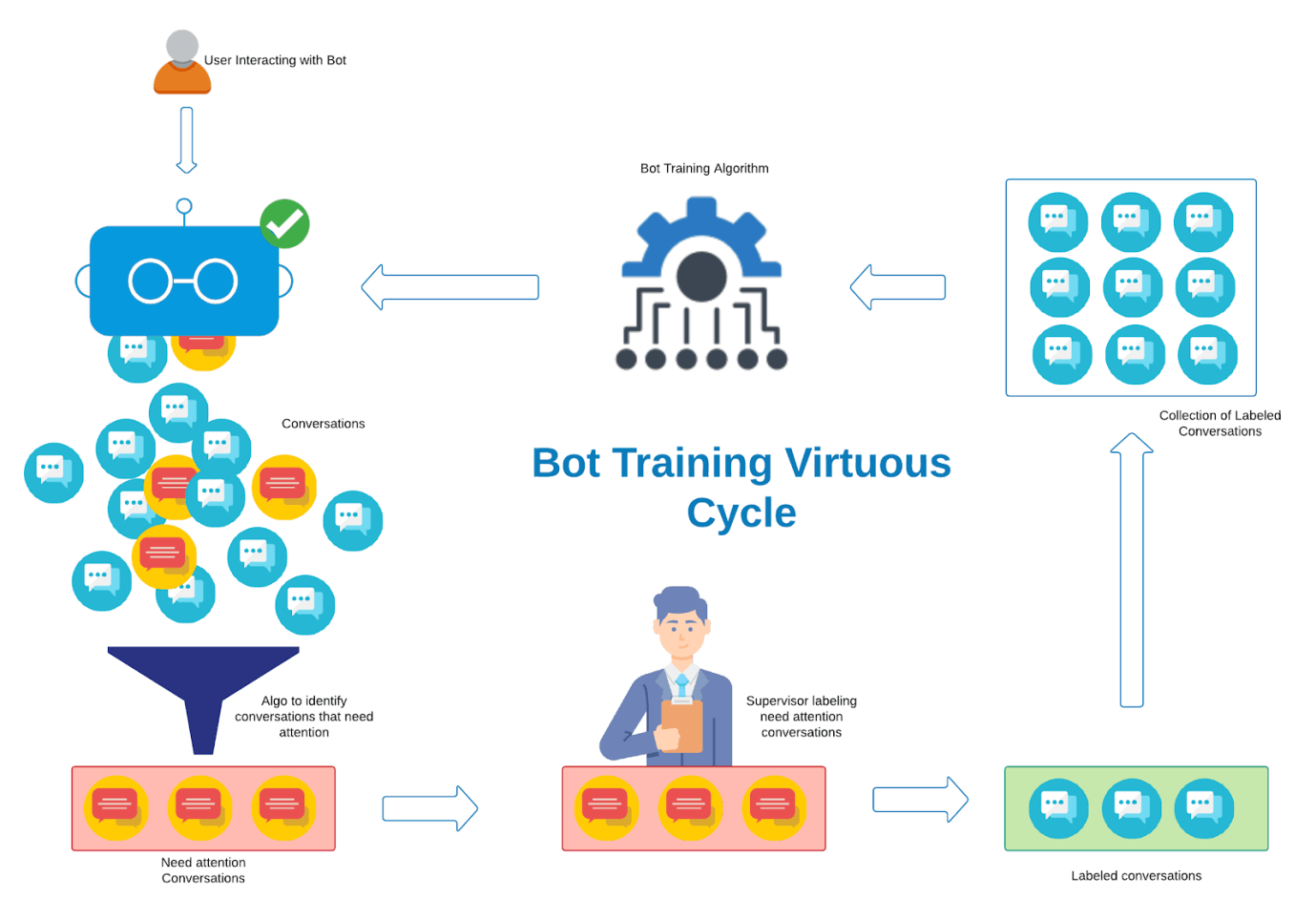
Enterprise Virtual assistants can be launched once they are fully trained. However, for that to happen, they need to interact with real users (which can only happen post-launch). To overcome this catch22 situation, enterprises run a pilot before the grand launch. While pilots solve the problem to some extent, enterprises are generally very keen on reaching the 100% training mark faster. Therefore it is essential to accelerate training immediately after the solution is made generally available.
Smartbots team has developed a solution to streamline this virtuous cycle of bot training. This cycle has 4 steps:
1. Identifying the conversations that need attention
2. Automating the training process
3. Taking human help to correct the conversations that need attention
4. Re-training the model to update the bot
Identifying Conversations Which need Attention
While building the Intelligent Virtual Agents, various flows are conceptualized. These are called standard conversation flows. Scenarios where the flow deviates from the standard flows, where the conversations indicate that the user query is not completely addressed are categorized as need attention conversations.
Identifying the need attention conversations simplifies the process of training the bot as the burden of manually going through all the conversations and labeling them can be avoided.
Here are two methods to identify the need attention conversations
1. Flow deviation method
2. Logistic regression based conversation classification method
Flow Deviation Method
A simple approach to identify need attention conversations is to classify all conversations which deviate from the standard conversation flow. This approach fits for the use-cases where the number of conversations generated is less and when the conversation flow is simple. Ex: Bot helping employees raise a support ticket. This flow detection method is not very effective where large volumes of conversations are generated.
Logistic Regression Based Conversation Classification Method
Before we look into the classification method, let’s look at the fundamental unit used in this method – a conversation vector.
Conversation Vector
Every conversation can be converted into a feature vector called a conversation vector. A conversation vector is a multidimensional vector of floating-point numbers that represent the nature of the conversation. Conversations that are similar in nature are mapped to proximate points in the n-dimensional space. Two conversations that are about the same topic and similar flow have similar conversation vectors. Conversation vectors can also be used to determine if the conversations are fulfilled, and if the party seeking information is completely satisfied with the other party’s response.
A Simplified Representation of the Conversation Vector is here Under:
Conversation 1:
User1: Hey, I want to reset my system password
User2: Sure, please give me your user-id
User1: It’s 1234
User2: Got it. I have raised a ticket. You will get an update in 24 hrs
User1: Thanks, that was helpful
User2: You are welcome
Conversation 2:
User1: Hey, I want to reset my system password
User2: Sure, please give me your user-id
User1: It’s 1234
User2: Got it. I have raised a ticket. You will get an update in 24 hrs
User1: Oh no. I want an immediate resolution.
User2: I am afraid you might have to wait
User1: That’s bad. Anyways, thanks.
User2: You are welcome
The Conversation Vectors for the above Conversations is as below:
Conversation vector [topic, conversation type, fulfillment status, sentiment, satisfaction]
Conversation 1 vector = [23, 29, 0.97, 0.77, 0.98]
Conversation 2 vector = [23, 29, 0.92, 0.37, 0.22]
Conversation Classification Method
Let’s See How the Classification Model is Developed:
1. Take a collection of conversation logs. Identify the dimensions. This is our dataset
2. Purify the dataset
3. Divide the dataset into training dataset (70%), and test dataset (30%)
4. Label the training dataset as ‘need attention’ or ‘successful’, whichever suits best.
5. Labeled conversation logs are then used to train the model using logistic regression
6. The model is tested against the test dataset
Now that the model is available, it can be deployed on to an endpoint. Any new conversation can be categorized as need attention by sending the conversation to this model.
Once the need attention conversations are identified, the next step is to label them.
Automating the Training Process
Auto training works in those cases where the user provides feedback. Feedback helps in flow corrections. Here is an example of a conversation that can be trained automatically (without human intervention).
User: Hey, I want to reset my system password as per the new password policy.
Bot: Sure, for information on password policy, please follow the link: https://passwordpolicy_link.
Did that answer your query? (Yes) (No)
User: No
Bot: Oh. Looks like I got it wrong. Is your query about resetting your password?
User: Yes, that’s right
Bot: Thanks for providing clarity. I created a password reset request.
Taking Human Help to Label Needs Attention Conversations
Supervised training by humans is the best approach to improve the Agent Assistant Chatbot quality. However, going through the full set of conversations, and identifying conversations that need human attention can significantly reduce the burden on manual training. For Example, from a list of 1000 conversations, if the algorithm identifies 100 conversations that need attention, the burden of training reduces by 10 times.
As a part of supervised training, the following tasks are performed:
1. Identifying mismatched intents
2. Identifying missed entities
Once the need attention conversations are trained, they are made available for re-building the bot.
Re-Build the Model to Update the Bot
Once enough labeled logs are available, a job is triggered to run the bot training algorithm. The job runs during low demand time so as to make a smooth transition. The algorithm adds new knowledge into the bot to make it smarter.
This way, the initial bot is now trained and updated, thereby enhancing the quality and stability of the bot on a continuous basis.
Share this article by link or share it with your team